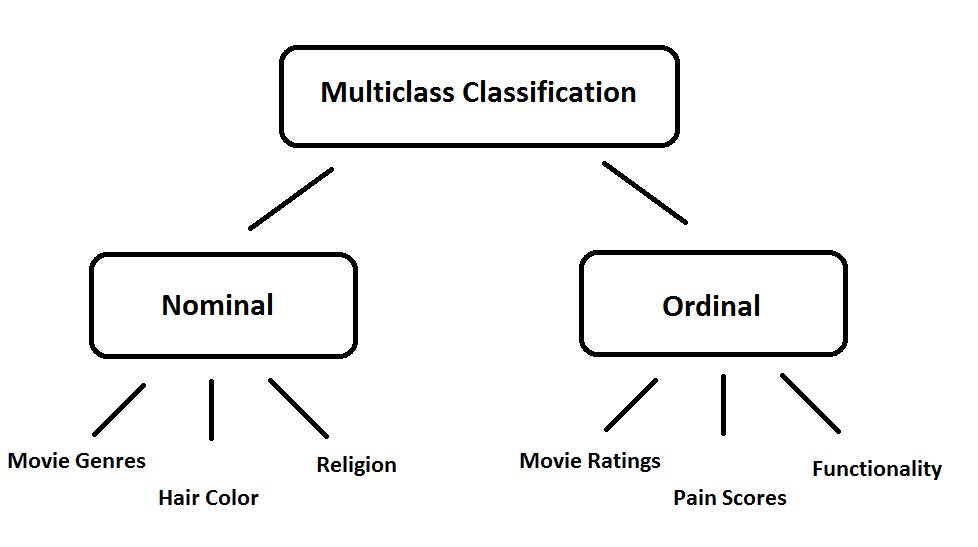
For this blog, I want to write an article about multi-class problems in machine learning. Multi-class classification is the process of classifying instances into three or more classes (the target variable).
However, not all dependent variables should be considered the same. Depending on the type of problem, the target is either nominal or ordinal.
Nominal values are classes where there is no apparent order. Examples of nominal values can be movie genres, hair colors, and religions.
Ordinal values are classes where there is order. Ordinal values explain a “position” or “rank” among the other targets. Examples of ordinal values can be movie ratings, hospital pain scores, and levels of functionality.
To elaborate further on ordinal data, I’ll use the Tanzanian water pump dataset from the “Pump it Up” competition accompanied with Dolci (https://github.com/dolcikey) and Eunjoo’s (https://github.com/stereopickle) approach to this challenge.
Pump it Up: Data Mining the Water Table
The data set comes from Taarifa and the Taznanian Ministry of Water. The objective is to predict whether a water pump is:
1. Functional
2. Needs Repair
3. Non Functional
Nominal Logistic Regression
LogisticRegression(solver=’saga’, penalty=’l2', multi_class=’multinomial’)
This is the first instance where I encountered the possible problems of assuming all classifications equal(all nominal). From the the top row(True Value: non functional), There are more cases where the model has predicted functional(1015 FN) than needs repair(810 FN).
The model has treated each class being independent from the other dependent classes. However, it would be awesome if the model took into account ranks. As in, there should be more “needs repair” false negatives than “functional” false negatives from the top row(True Label: non functional)

LogisticRegression(solver=’saga’, penalty=’l2', multi_class=’multinomial’)Training Recall: 0.6953017636280349
Testing Recall: 0.6514309764309765
Training F1-Score: 0.6941810385966073
Testing F1-Score: 0.6884061761379136Training Accuracy-Score: 0.6953017636280349
Testing Accuracy-Score: 0.6514309764309765
Ordinal Regression
Many credits to Fabian Pedregosa-Izquierdo who put together a working ordinal regression package. He admits there are some wrinkles that still need to be ironed but I can’t explain the complexity of his problem.
mord.LogisticIT()
Using mord.LogisticIT()the Accuracy Score and F1 Scores are lower from the vanilla nominal logistic regression. However, I prefer this model because the “extreme” false negatives have been minimized.
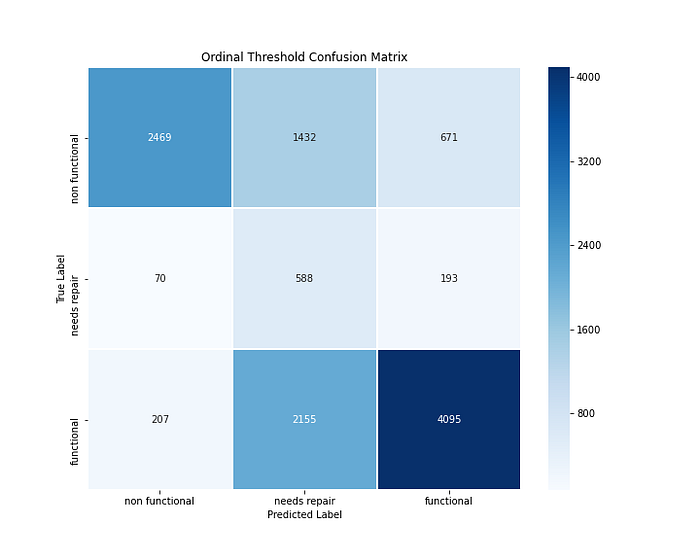
mord.LogisticIT()Training Recall: 0.6572320288690303
Testing Recall: 0.6663747579340547Training F1-Score: 0.6572320288690303
Testing F1-Score: 0.6663747579340547Training Accuracy-Score: 0.6570087036188731
Testing Accuracy-Score: 0.602020202020202
mord.OrdinalRidge()
Using mord.OrdinalRidge(), the “extreme” false negatives have decreased even further, however the model predicted mostly “needs repair.” Pretty cool stuff!
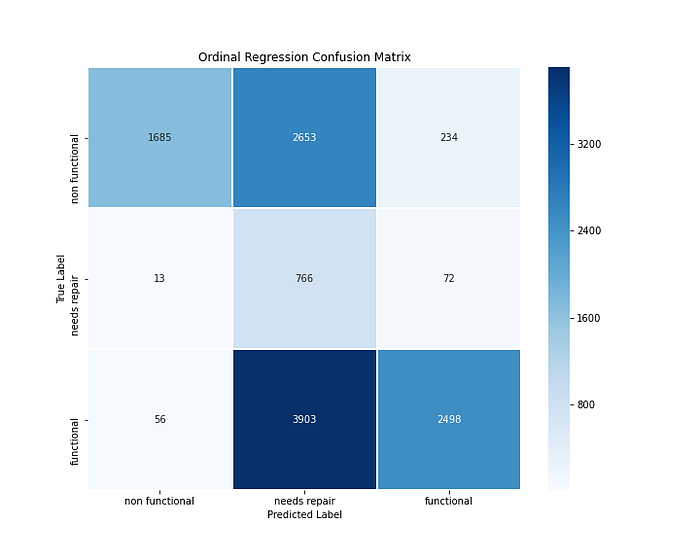
mord.OrdinalRidge()Training Recall: 0.5898992212551535
Testing Recall: 0.4165824915824916Training F1-Score: 0.5713714015670647
Testing F1-Score: 0.5116547216164992Training Accuracy-Score: 0.5898992212551535
Testing Accuracy-Score: 0.4165824915824916
Future Steps
F1 score takes a balanced approach for both precision and recall. I wish there was a metric where false negatives were weighted depending on how close the predicted value is to the true value. I googled some discussions about this topic and “Somers’ Dxy rank correlation” came about.
In addition, it would be interesting to use RMSE. Although normally used for continuous values, it might be cool to see how hypertuning off of RMSE would do.
To be quite honest, all of this is pretty confusing as it is. If anyone can recommend any material I can read up on, please let me know!
LGBMRanker + K-Means Clustering
I also wanted to use LTR(Learning-To-Rank) classifier to return a 1-D array of unique ranks. From which, I can cluster by the number of unique classes. However, I’m also not sure if this is mathematically sound. I’m open to any suggestions, please let me know!
