Albert UmPlotting Bollinger Bands with Plotly Graph ObjectsFor this blog, I will demonstrate how to plot Bollinger Bands using Plotly. Bollinger bands contain upper/lower bounds(±2 standard…May 17, 20211May 17, 20211
Albert UmUsing Stock Data for Classification Problem: ActionThis blog will demonstrate a simple way to frame financial stock data into a sequence classification problem. The business case is to…May 9, 2021May 9, 2021
Albert UmLoad Data CSV into MySQLFor this blog, I will import a CSV file to a MySQL server(using MAMP) to create a practice platform for SQL statements. More specifically…Apr 28, 2021Apr 28, 2021
Albert UmChi-Squared Test for IndependencePearson’s chi-squared test for independence is used to test whether there is an association between categorical variables by seeing if…Apr 26, 2021Apr 26, 2021
Albert UmSummary of Agile: ScrumAgile is an approach to project management that aims always to have a working product while continuously improving in short increments…Apr 15, 2021Apr 15, 2021
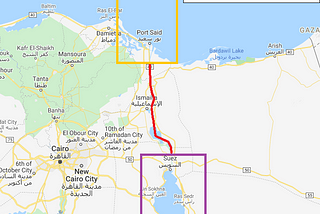
Albert UmSuez Canal Blockage: Queue Backlog with Sentinel-1 SAROn March 21, 2021, a massive container ship, Ever Given, was found stuck in the Suez Canal. The Suez Canal is an important trade route as…Apr 9, 2021Apr 9, 2021
Albert UmClassification: Class ImbalanceFor this blog, I will demonstrate three techniques to handle class imbalance using NYS PUMS(Public Use Microdata Sample) Census data. (You…Apr 5, 2021Apr 5, 2021
Albert UmPump it Up: Data Mining the Water Table — Population AnalysisFor this blog, I will run a hypothesis test if the population count around a well affects its functionality. I will be using the dataset…Mar 28, 2021Mar 28, 2021
Albert UmL1, L2 Regularization in XGBoost RegressionRegularization in gradient boosted regression trees are applied to the leaf values and not the feature coefficients like in lasso/ridge…Mar 21, 20211Mar 21, 20211
Albert UmAbsorbing Markov Chain: Limiting MatrixI recently came across an interesting problem that required some understanding of Absorbing Markov Chains. The objective to calculate the…Mar 15, 2021Mar 15, 2021